
How diffusion models create AI images
Diffusion models are the backbone of modern AI image generation. They power many of today’s most recognizable AI art tools and have reshaped how computers learn to create images from text descriptions, sketches, or reference visuals. While the mathematics behind diffusion can be complex, the underlying idea is surprisingly intuitive: learn how to remove noise from an image, step by step, until a coherent picture appears.
This article explains diffusion models from the ground up, moving from simple concepts to more advanced mechanisms, with a focus on clarity, accuracy, and long-term relevance.
The core idea behind diffusion
At their heart, diffusion models learn how images are destroyed and then how to rebuild them.
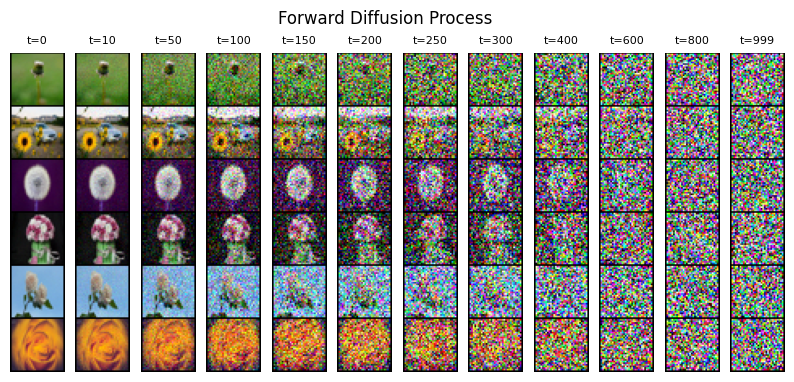
The training process starts with real images. These images are gradually corrupted by adding random noise over many small steps. Eventually, the original image becomes pure static. This forward process is fixed and does not involve learning; it is a controlled way to turn structured data into randomness.
The model is trained to reverse this process. Given a noisy image and information about how much noise was added, it learns to predict and remove that noise. By repeating this denoising operation many times, the model learns how to reconstruct realistic images from noise alone.
In practical terms, image generation works by starting with random noise and letting the model iteratively refine it into a meaningful visual.
Why noise matters in image generation
Noise is not a flaw in diffusion models; it is a feature.
By learning to remove noise at different levels of corruption, the model develops a deep understanding of visual structure. Early denoising steps handle large-scale composition, such as shapes and layout. Later steps refine fine details like textures, edges, and lighting.
This gradual refinement is one reason diffusion models produce images that feel coherent and visually rich. Instead of generating an image in a single step, they build it progressively, correcting errors along the way.
The forward diffusion process
The forward process is a mathematical recipe that adds Gaussian noise to an image over a predefined number of steps.
Key characteristics of this process include:
- The noise is added in very small increments
- Each step slightly degrades the image
- After enough steps, the image becomes indistinguishable from random noise
- The process is fully known and does not require training
Because the forward process is predictable, the model can be trained specifically to undo it.
The reverse diffusion process
The reverse process is where learning happens.
At each step, the model receives:
- A noisy image
- A time step indicating how much noise is present
The model predicts the noise component and subtracts it from the image. Repeating this process gradually transforms noise into structure.
Although this happens over dozens or hundreds of steps, each individual step is relatively simple. The complexity emerges from how these steps interact over time.
Neural networks used in diffusion models
Most diffusion models rely on a variant of the U-Net architecture, a type of neural network originally designed for image segmentation.
U-Nets are well suited for diffusion because:
- They capture both global structure and fine detail
- They process images at multiple resolutions
- They efficiently reuse information through skip connections
These properties allow diffusion models to maintain coherence across large areas of an image while still producing sharp details.
Conditioning: guiding the image generation
Unconditional diffusion models generate random images. To make them useful, they are usually conditioned on additional information.
Common conditioning methods include:
- Text prompts describing the desired image
- Reference images or sketches
- Depth maps or edge detections
- Style embeddings or artistic constraints
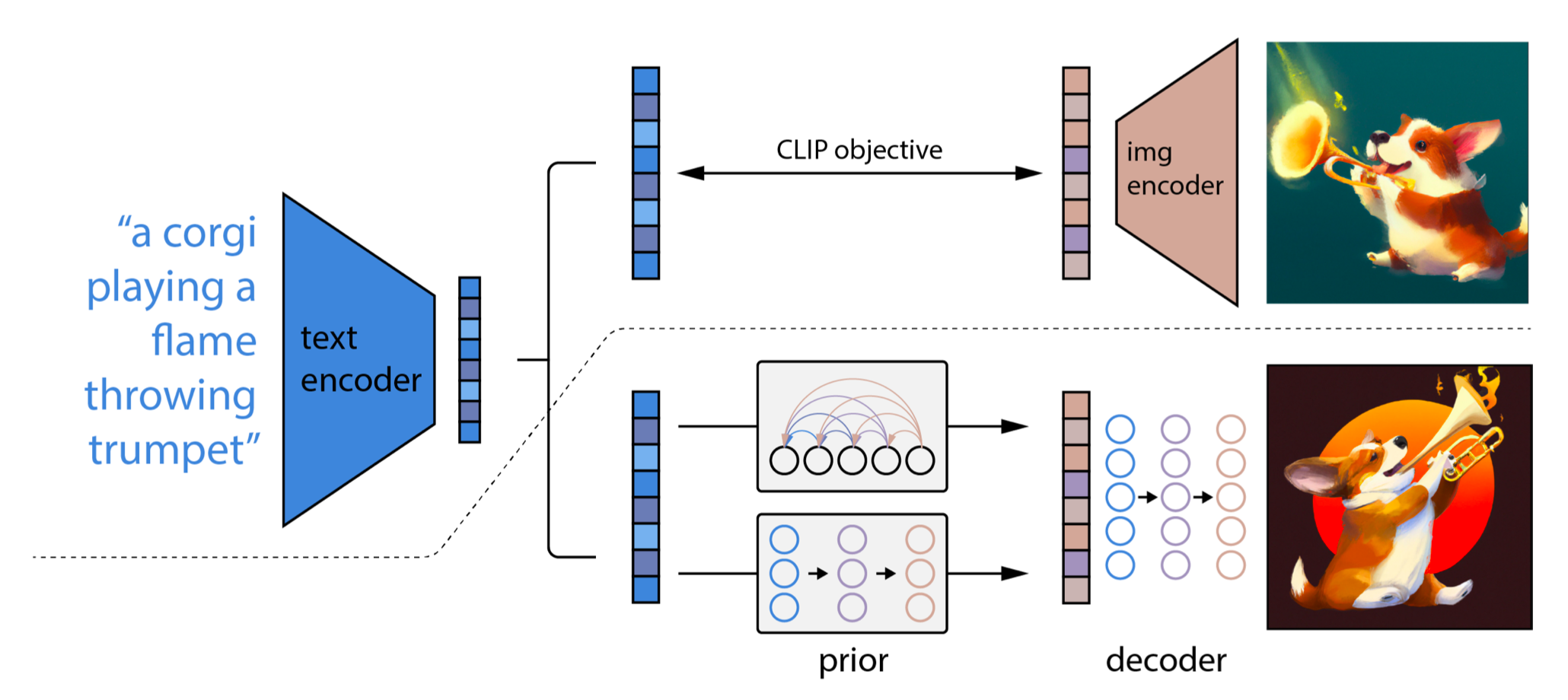
Text conditioning is typically achieved using a separate text encoder that transforms words into numerical representations. These representations guide the denoising process, nudging the model toward images that match the prompt.
This is how models such as Stable Diffusion and DALL·E can translate natural language into visuals.

Latent diffusion and efficiency
Early diffusion models operated directly on full-resolution images, which required significant computational resources. Latent diffusion introduced a major optimization.
Instead of working in pixel space, images are first compressed into a lower-dimensional latent space using an autoencoder. The diffusion process happens in this compressed representation, and the final result is decoded back into an image.
Benefits of latent diffusion include:
- Faster generation times
- Lower memory usage
- The ability to scale to higher resolutions
- Reduced training costs
This approach is one reason diffusion models became widely accessible and deployable on consumer hardware.
Sampling strategies and speed
Generating an image involves repeatedly applying the reverse diffusion step. The number of steps directly affects quality and speed.
Researchers have developed advanced sampling methods to reduce the number of required steps without sacrificing visual fidelity. These methods change how noise is removed and how steps are scheduled.
While the underlying model remains the same, better sampling can dramatically improve usability, making diffusion-based tools practical for everyday creative work.
Strengths of diffusion models in AI art
Diffusion models dominate AI image generation because of several key advantages:
- High image quality with realistic textures and lighting
- Strong alignment with text prompts
- Stability during training compared to earlier generative models
- Flexibility across styles, subjects, and resolutions
Unlike adversarial approaches, diffusion models do not rely on competing networks, which simplifies training and reduces instability.
Limitations and trade-offs
Despite their strengths, diffusion models are not without drawbacks.
Common limitations include:
- Slower generation compared to single-pass models
- High computational cost for training
- Sensitivity to prompt phrasing and conditioning quality
- Difficulty maintaining precise spatial control without additional tools
Ongoing research focuses on addressing these issues through better architectures, improved conditioning, and hybrid approaches.
Diffusion models and artistic control
One of the most important developments in diffusion-based AI art is the rise of control mechanisms.
Techniques such as guidance scales, conditioning weights, and structural inputs allow creators to balance creativity and precision. This enables use cases ranging from abstract art to highly controlled design tasks.
Rather than replacing artistic intent, diffusion models increasingly act as collaborative tools, translating human guidance into visual form.
Where diffusion models are heading
Diffusion models continue to evolve beyond static image generation. They are being extended to video, 3D assets, and multimodal systems that combine text, image, and audio understanding.
As these models improve, the core principle remains unchanged: learn how to reverse noise into structure. This simple idea has proven powerful enough to redefine how machines create images and how humans interact with visual creativity.
Diffusion models are not just a technical breakthrough. They represent a new way of thinking about generation itself, where creation emerges gradually, guided by probability, structure, and intent.